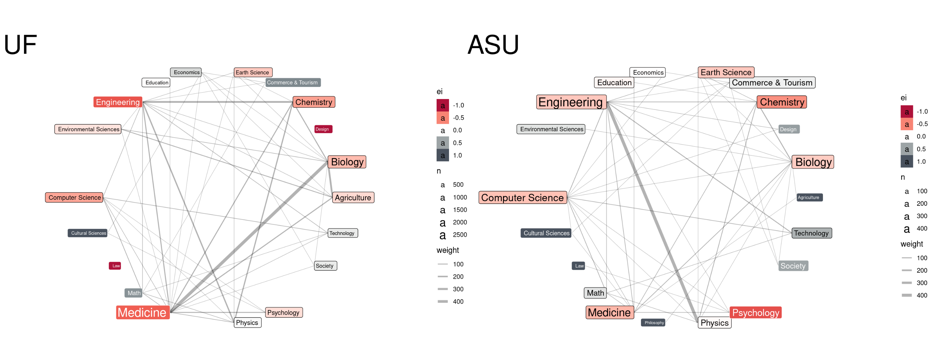
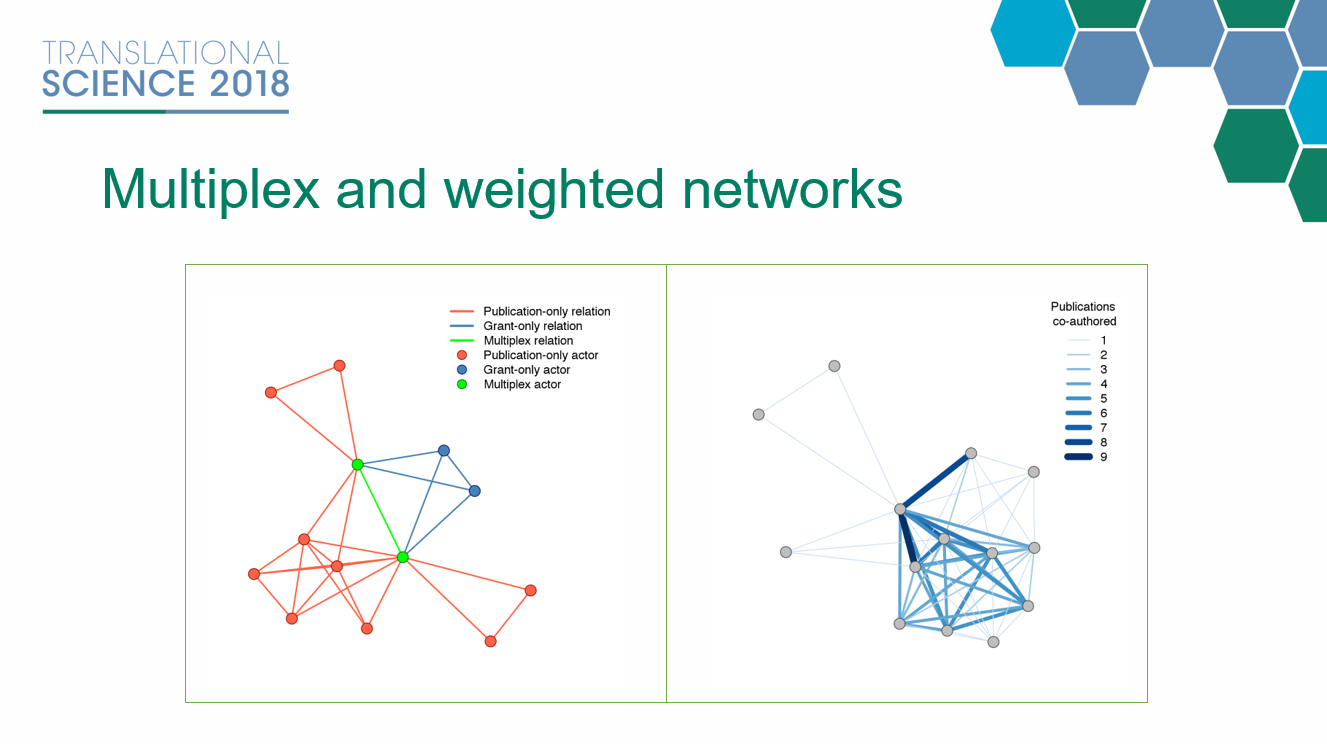
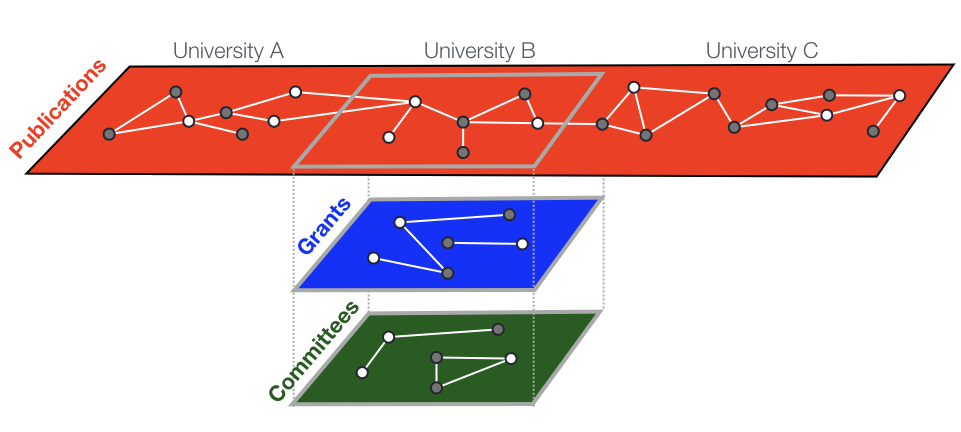
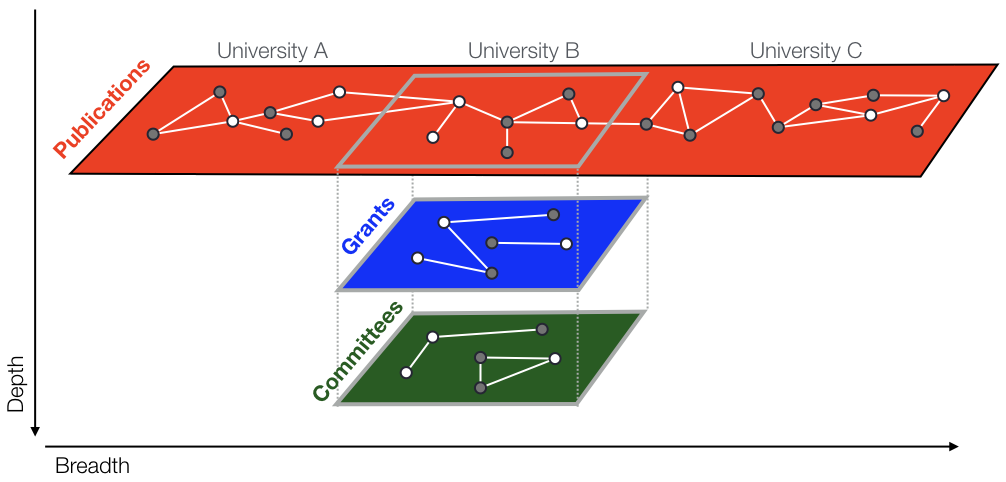
The more bountiful the fruits of our labor the more we guard them from other researchers[1]. Data collection costs are particularly high in certain fields. Criminological data, for example, typically contain sensitive information on criminal behavior and victimization, which makes them more highly protected and at times inaccessible. However, with the recent developments in data science and computing this once elusive data have become much more accessible, provided you have the tools and the know-how[2]. This article shows an example of how free software tools can be used to scrape criminological data from the web to study crime and victimization patterns in US cities.
The tool, in this case, is the R project, a completely free, open-source software environment and programming language designed for statistical computing and graphics. The community of R users has been expanding exponentially in recent years[3]. This has led to the development of a vast array of freely available “add-on” packages to perform tasks which move far beyond the scope of other statistical software such as Stata, SAS, and SPSS. The sweeping versatility of R relative to its competitors allows for creative solutions to collecting traditionally elusive crime data.
One of the traditional approaches to examining crime is via the analysis of official records. Typically this would require that we approach Police Departments, Prisons, and other criminal justice agencies in the hope that we might be granted access to the necessary data. However, in the age of the Internet many criminal justice agencies publish information online. One well-known example is the Uniform Crime Reports (UCR), published annually by the Federal Bureau of Investigation (FBI). The UCR includes swathes of information on nationwide crime, law enforcement deaths and assaults, and hate crimes.
While a lot information can be gained from national data sources such as the UCR, many criminological researchers are interested in crime at a more local level. Unfortunately, this is the level where crime statistics become more sensitive and difficult to access. That said, many local police departments have been quietly publishing official records on individual arrests, incidents, citations, ordinance violations, and traffic accidents to the ‘daily bulletin’ boards found on their respective websites. The result is an extraordinary wealth of untapped local crime data available online, in some cases for as long as a decade. R and its packages can be used to “web scrape” these data sources.
Web scraping is an automated, systematic approach to extracting and refining online information. In the social sciences it is most often used to collect data from social media and networking websites such as Twitter, Facebook, LinkedIn and the like. Open source software such as MassMine and R packages such as twitteR have helped streamline data scraping, becoming popular tools for downloading tweets, statuses, and posts[4]. While these tools target social networking websites, web scraping targets the underlying text-based HTML code composing both these and other websites. R functions can recognize patterns in HTML code (such as HTML start and end tags), extract raw text from HTML pages, and convert that text into a dataset that is amenable to statistical analysis.
We used base R in conjunction with RSelenium, a package designed to automate website navigation, to scrape police incident data from the Gainesville Police Department website and six other US police departments (Union County PD, South Carolina; Wilmington PD, North Carolina; Cedar Hill PD, Texas; Cleveland County PD, North Carolina; Concord PD, North Carolina; Wood County PD, Ohio). The raw data includes roughly 1.6 million incidents from 2007 to 2017 with information on the individuals and locations involved in arrests, citations, summons, ordinance violations, victimizations, and traffic accidents. Each observation also identifies the responding police officer and the time of the incident down to the minute. We focus on victimizations, information on the offenses committed against citizens or institutions which violate the law and subsequently reported to the respective police departments by the victims, and arrests, information on the offenders who have been formally apprehended[5] by the police for committing one or more of these offenses. Table 1 and Figure 1 show some of the information that can be obtained from the Gainesville, FL arrest and victimization data.
Table 1. Characteristics of Arrests and Victimizations in Gainesville, FL between 2007 and 2017
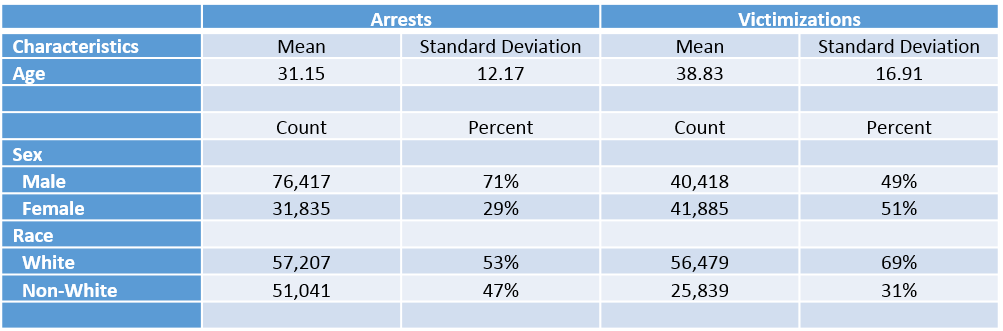
Figure 1. Monthly Arrests and Victimization in Gainesville, FL between May 2007 and April 2017
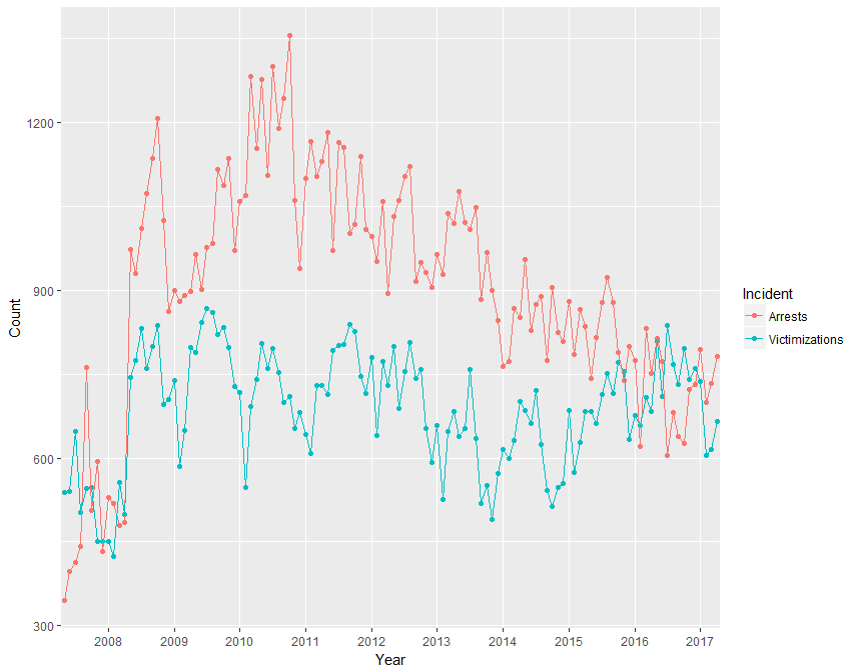
In addition to traditional statistical description and modeling of crime patterns, these data can be used to map ‘co-offending networks’ – networks of people who commit crimes together. It is well-known that crime is often committed by groups[6]: it is a form of human interaction, and it can be analyzed as a social network[7]. Two individuals are co-offenders if they are arrested during the same incident: in a social network this produces a link between them. As an example, we constructed a co-offending network using the decade of arrest data scraped from the Gainesville Police Department website. This network consists of 34,822 people (nodes) distributed in 28,887 disconnected components. The largest component (Figure 1) consists of 834 people[8]. This could be a group of interrelated gangs, or groups of University students co-offending with their peers. In this figure, the size of the node represents the number of experienced victimizations, the larger the node the more victimizations. Arrests are represented by the node color, the ‘hotter’ colored nodes representing a greater number of arrests. This allows us to examine the ‘victim-offender overlap’, the consistently replicated observation that victims of crime are often known offenders[9]. Co-offending networks can also be used to identify subgroups, such as gangs or crime families; detect the most central offenders, who participate in criminal activities with many other partners; and examine how crime “partnerships” and groups form.
The potential of web scraping is limited only by the information available online. Whenever there are data embedded in any given website’s HTML, it is possible to use web scraping techniques to access and refine these data. Consequently, web scraping need not be limited to a single source or type per project. For example, we plan to scrape hourly weather data from Weather Underground, and merge them with the arrest data. Research has long found that violent crime, including assault, domestic violence, and to a lesser extent homicide, become more frequent as temperature increases[10]. The arrest and weather data obtained via web scraping could allow us to examine the relationship between weather and crime more in-depth. The Internet also houses information which could let us examine cultural events (e.g. movie openings) and victimization by scraping data from websites such as boxofficemojo.com, or natural disasters and looting by incorporating data from the Federal Emergency Management Agency (FEMA). The knowledge from such projects could help local law enforcement better plan their activities based on weather forecasts, expected foot traffic from cultural events, predict looting targets following hurricanes, and beyond.
R-supported web-scraping techniques provide wide access to vast quantities of up-to-date information on an almost unlimited range of topics. As an affordable and easily reproducible mode of data collection, they have the potential to drastically transform the way we do research about crime and human interactions[11].
Figure 2. Gainesville, FL Co-offending Network from May 2007 to April 2017
[1] Kitchin, R. (2014). The Data Revolution: Big Data, Open Data, Data Infrastructures & Their Consequences. Washington, DC: SAGE
[2] And, of course, the approval of your Institutional Review Board.
[3] Tipperman, S. (2015). Programming tools: Adventures with R. Nature News, 517(7532), 109.
[4] Thomson, R. and Vacca, R. (2018) Collecting and Analyzing Big Data on a Small Budget. Bureau of Economic and Business Research.
[5] But not necessarily charged or sentenced.
[6] Warr, M. (2002) Companions in Crime: The Social Aspects of Criminal Conduct. New York, NY: Oxford University Press
[7] Papachristos, A. V. (2014) The Network Structure of Crime. Sociology Compass, 8(4): 347-357
[8] This is substantially more than the next largest component, which only consists of 28 nodes.
[9] Jennings, W. G., Piquero A. R., and Reingle J. M. (2012) On the overlap between victimization and offending: A reviewof the liteture. Aggression and Violent Behavior, 17: 16-26
[10] Cohn, E. G. (1990) Weather and Crime. British Journal of Criminology, 30: 51-64
[11] Munzert, S., Rubba, C., Meiβner, P., and Nyhuis, D. (2015) Automated Data Collection with R: A Practical Guide to Web Scraping and Text Mining. West Sussex, UK: Wiley
Author(s):Smith, Thomas Bryan; Vacca, Raffaele